
Traces by a Quick Sort on random sequence {100} (rand picking)
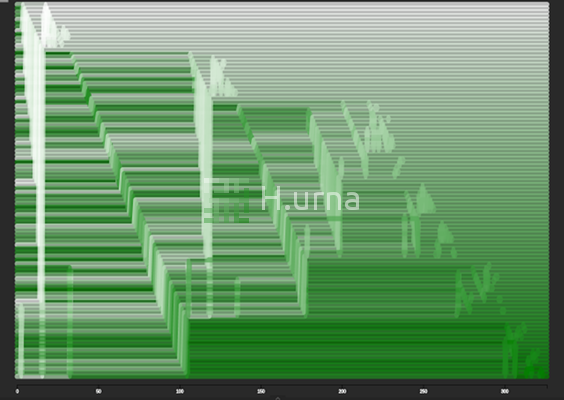
Swaps by a Quick Sort on random sequence {100} (rand picking)

Traces by a Quick Sort on reversed sequence {100} (rand picking)
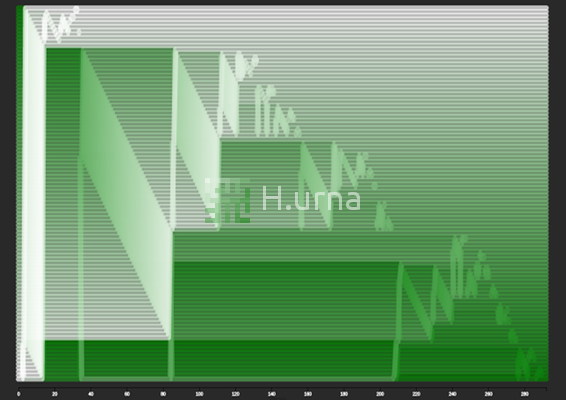
Swaps by a Quick Sort on reversed sequence {100} (rand picking)
Quick Access
 Play online
Play online
 C++ Source Code
C++ Source Code
Dependencies
- Use Partition-Exchange algorithm as a subroutine
How To Build
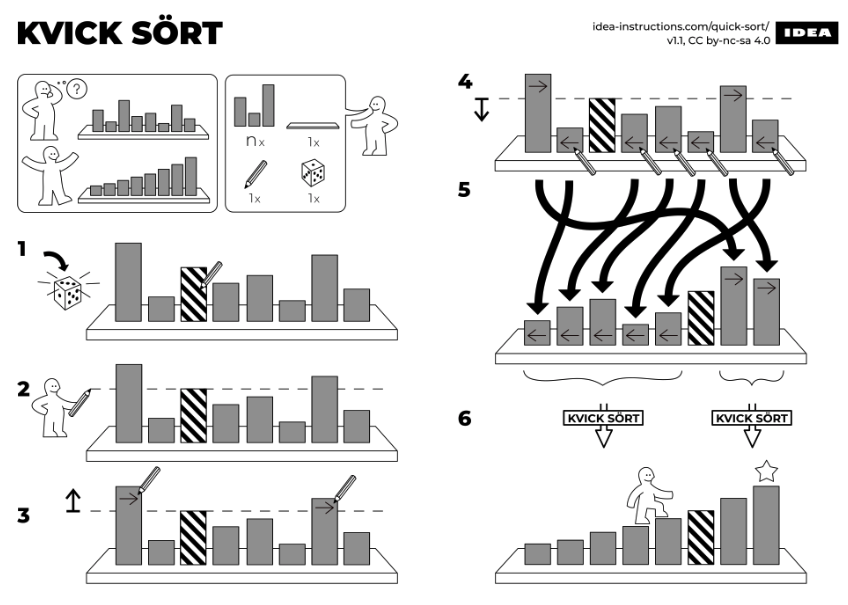
Quicksort (sometimes called partition-exchange sort) is an efficient sorting algorithm based on a divide and conquer approach. Quicksort first divides a large array into two smaller sub-arrays: the low elements and the high elements; it can then recursively sort the sub-arrays.
Steps
- 1. Pick an element, called a pivot, from the array.
- 2. Partition: divide the array into two partitions such that:
- All elements less than the pivot must be in the first partition.
- All elements higher than the pivot must be in the second partition.
- 3. Recurse on both sub-arrays resulting from the partition until part contains only a single element.
Code
void QuickSort (Iterator begin, Iterator end)
{
const auto size = distance(begin, end);
if (size < 2)
return;
// Pick Pivot € [begin, end] e.g { begin + (rand() % size); }
// Proceed partition
auto pivot = PickPivot(begin, end);
auto newPivot = Partition(begin, pivot, end);
QuickSort(begin, newPivot); // Recurse on first partition
QuickSort(newPivot + 1, end); // Recurse on second partition
}
Visualization
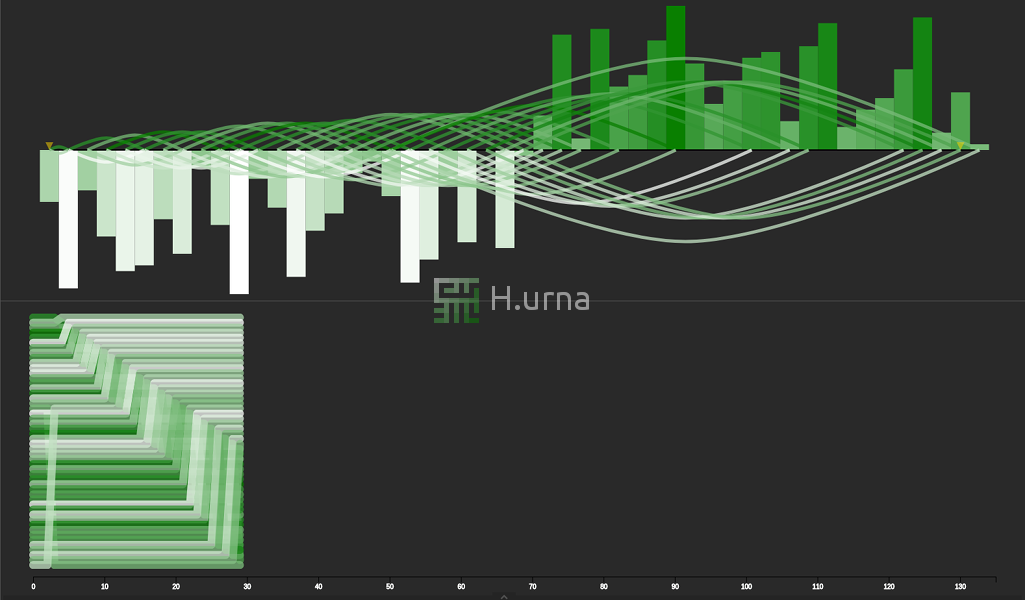
1. At the start of each partition, the pivot is moved to the end (the right/bottom) of the active subarray. 2. Partitioning then proceeds from left/top to right/bottom. At each step, a new element is added either of the set of lesser values (in which case a swap occurs) or to the set of higher values (in which case no swap occurs). 3. When a swap occurs, the left/top-most value higher than the pivot is moved to the right/bottom, to make room on the left for the new lesser value. Thus, notice that in all swap operations, only values darker than the pivot move to the right/bottom, and only values lighter than the pivot move to the left/top.
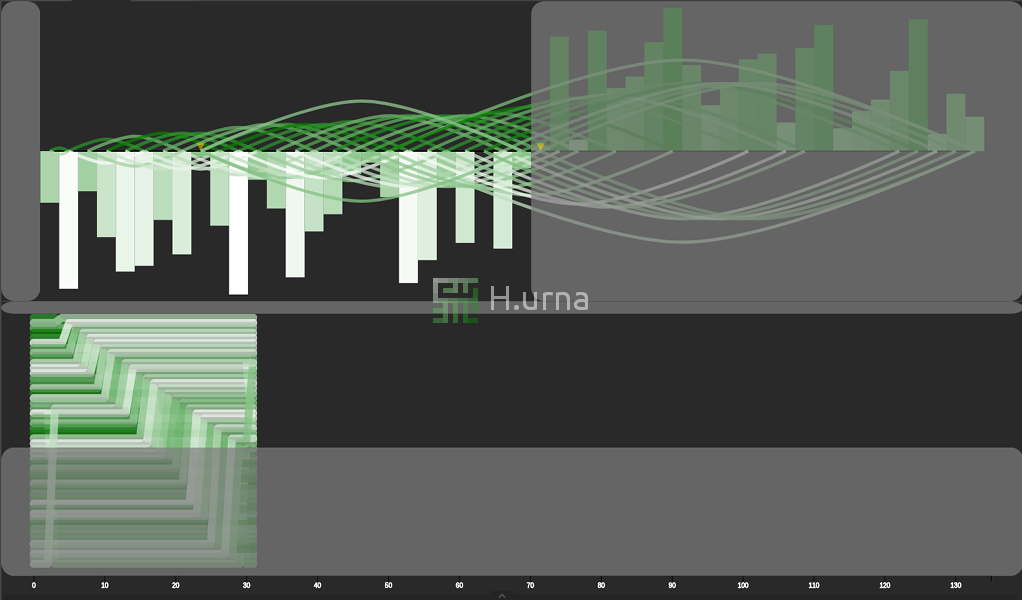
When the partition operation has visited all elements in the array, the pivot is placed in its final position between the two parts. Then, the algorithm recurses into the left part, followed by the right part (next slide).

This visualization doesn’t show the state of the stack, so it can appear to jump around arbitrarily due to the nature of recursion. Still, you can typically see when a partition operation finishes due to the characteristic movement of the pivot to the end of the active subarray.
Picking Strategies
As seen above, Quick Sort picks an element as pivot and partitions the given array around the picked pivot. The pivot selection can be made in several different ways and the choice of specific implementation schemes significantly affects the algorithm's performance. Here are some strategies:
- Always pick the first element.
- Always pick the last element.
- Always pick the middle element.
- Pick a random element.
- Pick the median (based on three value) as a pivot.
Let us visually compare these strategies under two different initial conditions. A reversed sequence and a random one:
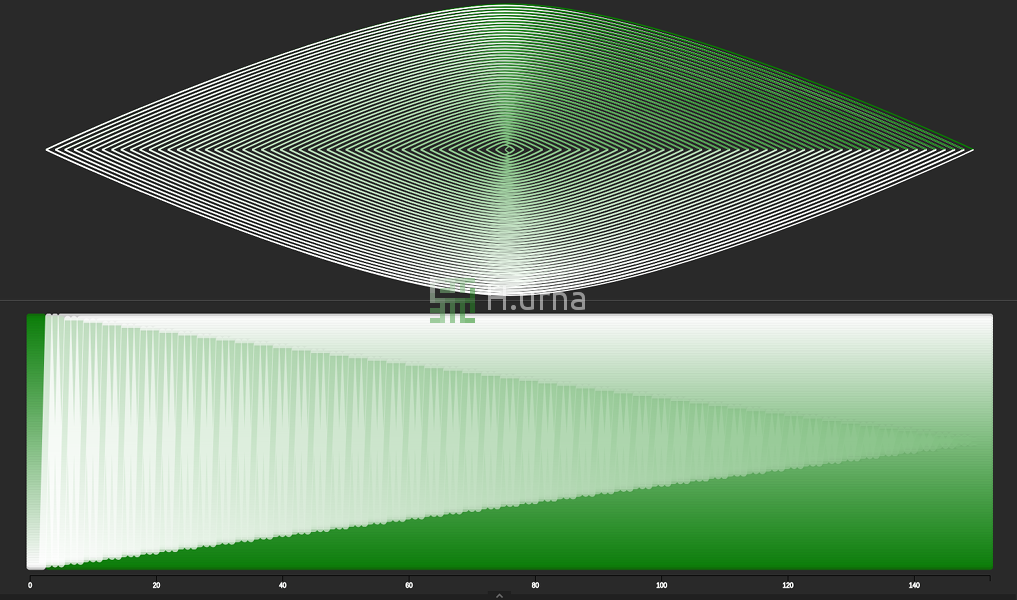
Quick Sort on a reversed sequence with a first element picking strategy: This is the worst case scenario: O(n2). You may notify fewer swaps. However, there is still n2 iterations and comparisons; play with it on H.urna.
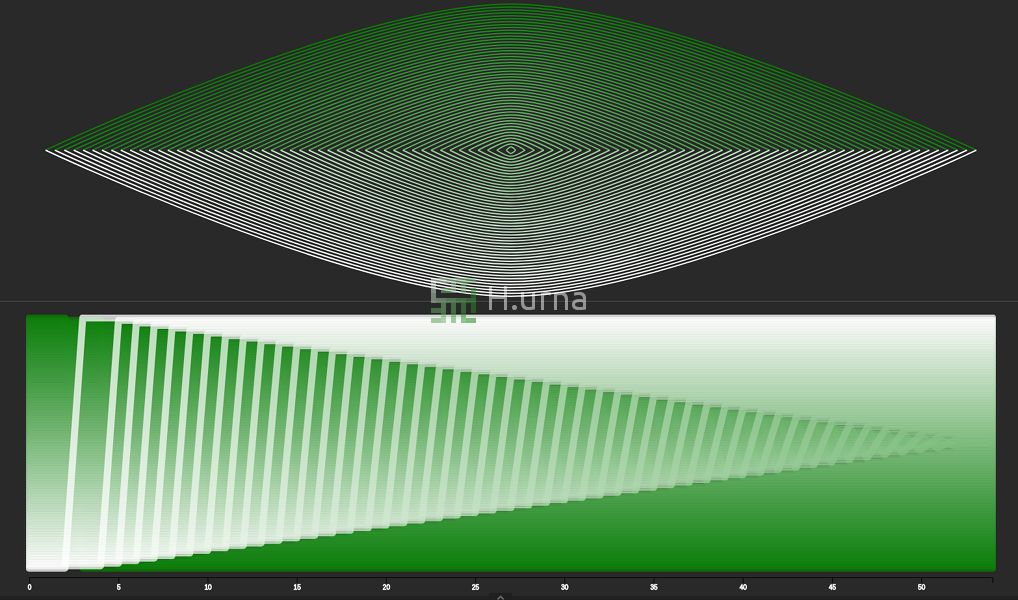
Quick Sort on reversed sequence with a last element picking strategy: This is the worst case scenario: O(n2). You may notify fewer swaps, however there is still n2 iterations and comparisons; play with it on H.urna.
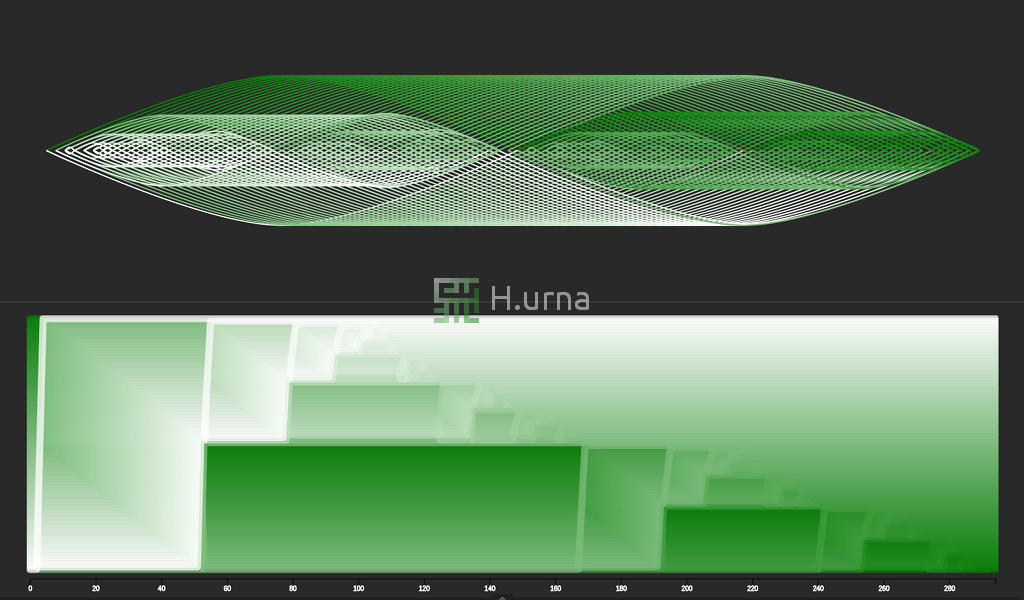
Quick Sort on reversed sequence with a middle element picking strategy: This is the best case scenario: O(n log n). Picking the middle element of a reversed sequence is equivalent to picking the median. (cf. median picking on next slide)
Quick Sort on reversed sequence with a three values median element picking strategy: This is the best case scenario: O(n log n). Picking the three values median element of a reversed sequence is equivalent to picking its exact median; resulting in the best cast scenario.
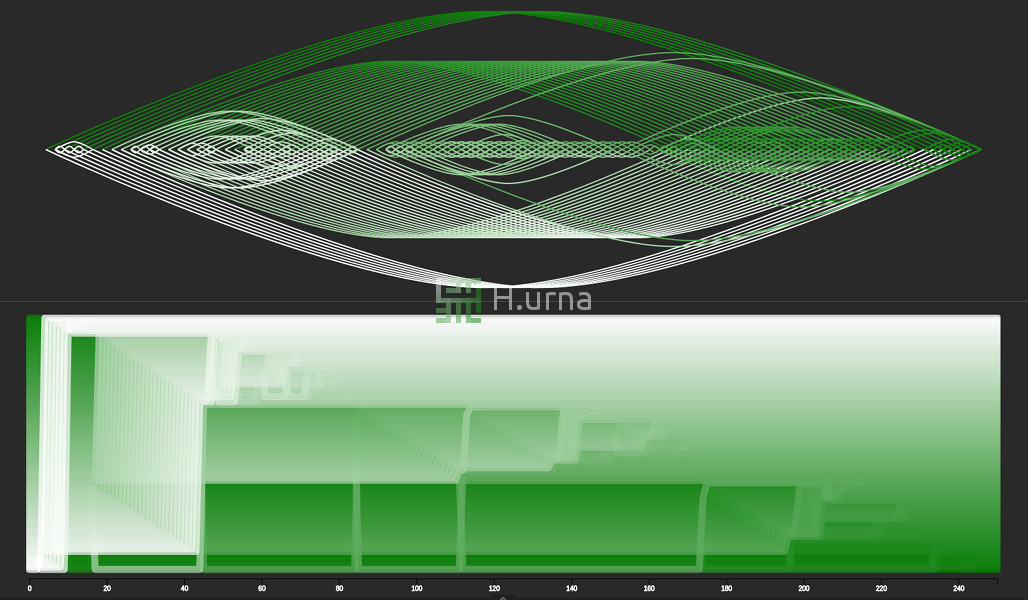
Quick Sort on reversed sequence with a random element picking strategy: This is the average case scenario: O(n log n).

Quick Sort on random sequence with a first element picking strategy: This is the average case scenario: O(n log n). You can typically see when a partition operation starts due to the characteristic movement of the pivot to the end of the active subarray.
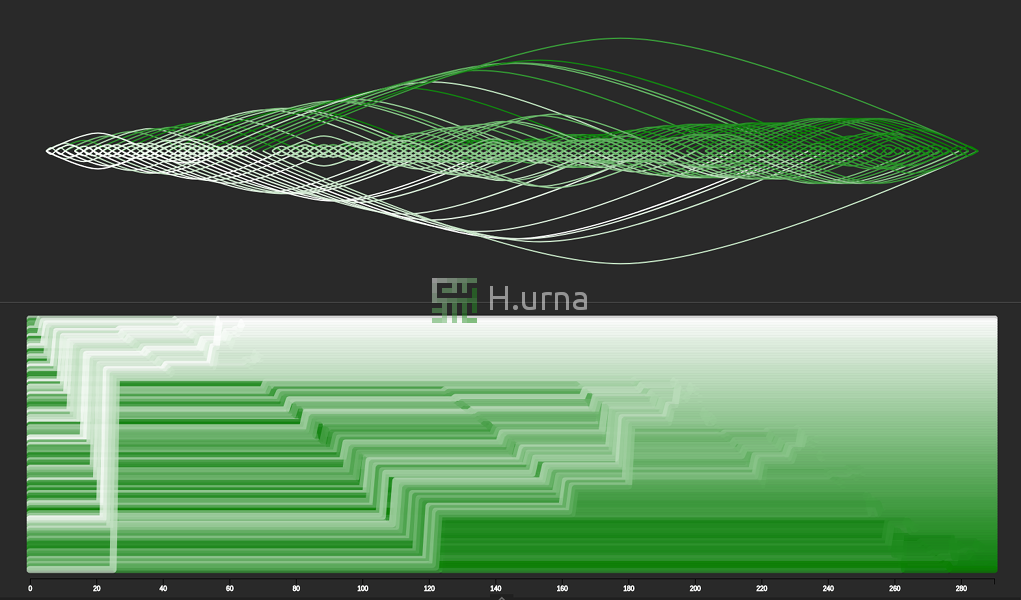
Quick Sort on random sequence with a last element picking strategy: This is the average case scenario: O(n log n). Here you cannot see the characteristic movement of the pivot as it is already to the end of the active subarray picked.
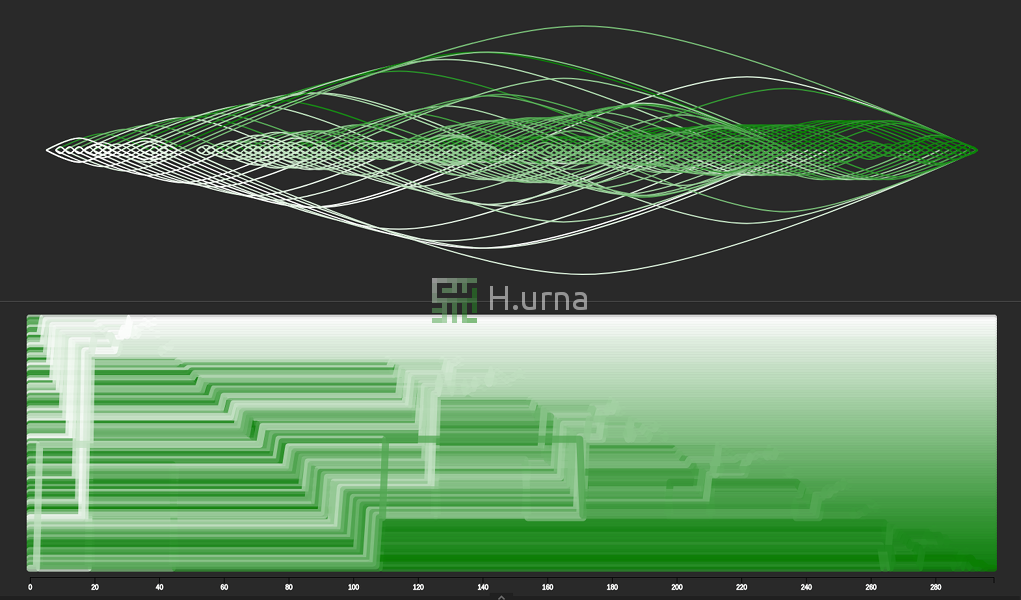
Quick Sort on random sequence with a middle element picking strategy: This is the average case scenario: O(n log n). you can typically see when a partition operation starts due to the characteristic movement of the pivot to the end of the active subarray.

Quick Sort on random sequence with a three values median element picking strategy: This is the average case scenario: O(n log n).

Quick Sort on random sequence with a random element picking strategy: This is the average case scenario: O(n log n). Here the random selection is a bit 'unlucky'.
Complexity
Reminder
The in-place version of a Partition has a time complexity of O(n) in all case and a space complexity of O(1).
Useful mathematical theorems:
| Math Sums | Master Theorem for Divide and Conquer Recurrences |
|---|---|
| $$\sum_{i=0}^{n-1} n = n(n-1)$$ | $$T(n) = O(n) + 2T(\frac{n}{2}) --> O(n log n)$$ |
| $$\sum_{i=0}^{n-1} i = \frac{n(n + 1)}{2} - n = \frac{n(n - 1)}{2}$$ | $$T(n) = O(1) + T(\frac{n}{2}) --> O(log n)$$ |
| $$\sum_{i=0}^{n-1} (n+i) = \sum_{i=0}^{n-1} n + \sum_{i=0}^{n-1} i$$ |
Time
Best
The best situation occurs when each Partition divides the sequence into two equal pieces (the median is picked). This means that after the first Partition, each recursive call processes a sequence of half the size. Let's put this into a recurrence relation: $$T(n) = O(n) + T(\frac{n}{2}) + T(\frac{n}{2})$$ $$T(n) = O(n) + 2T(\frac{n}{2})$$ Using the master theorem for divide-and-conquer recurrences: T(n) = O(n log n).
Worst
The worst situation occurs when each Partition-Exchange divides the sequence into two sublists of sizes 1 and n − 1 (smallest or most significant value is picked). Consequently, there are n − 1 nested call:
Sequences
$$a_0 = n$$ $$a_1 = n - 1$$ $$a_2 = n - 2$$ $$...$$ $$a_i = n - i$$
Computation
$$S(n) = \sum_{i=0}^{n-1} (n-i)$$ $$S(n) = \sum_{i=0}^{n-1} n - \sum_{i=0}^{n-1} i$$ $$S(n) = n(n - 1) - \frac{n(n - 1)}{2}$$ $$S(n) = \frac{n(n - 1)}{2}$$ $$S(n) = k(n^2 - n)$$ $$S(n) \approx O(n^2)$$
This occurs, for example using the last element as the pivot each time while having reverse order data.
Space
As a reminder: - In-place partitioning requires O(1) space. - One partition is recursively made one after on other. This is called tail recursion, meaning the right operates after the left has finished recursion. It implies that the right computation does not add to the left computation call stack.
Best: As seen on time complexity each recursive call processes a list of half the size. Let us put this into a recurrence relation for the call stack usage and use the master theorem for divide-and-conquer recurrences: $$T(n) = O(1) + T(\frac{n}{2})$$ --> O(ln n) space complexity (stack).
Worst: As seen in time computation there is n − 1 nested calls --> O(n) space complexity (stack).
Parallelization
Quicksort's divide-and-conquer formulation makes it amenable to parallelization using task parallelism. After the array has been partitioned first, the two sub-partitions can be sorted recursively in parallel.
Quicksort has some disadvantages when compared to alternative sorting algorithms, like merge sort, which complicate its efficient parallelization. The depth of quicksort's divide-and-conquer tree directly impacts the algorithm's scalability, and this depth is highly dependent on the algorithm's choice of the pivot.