Introduction
La liste chaînée est l'autre structure de données la plus fondamentale : comme un tableau, c'est aussi un moyen de stocker une collection d'éléments. Mais au lieu de stocker des données dans une mémoire contiguë fixe, une liste chaînée est une collection de nœuds reliés par des liens et ces nœuds peuvent être n'importe où dans l'espace mémoire.
Chaque donnée en mémoire a une adresse, nous pouvons toujours obtenir l'adresse d'une variable et symétriquement accéder à la donnée à partir de son adresse. L'idée est simple, nous avons donc accès au premier noeud qui contient : sa donnée ainsi que l'adresse du prochain nœud. Un pointeur null (nullptr) indique que la fin de la liste a été atteinte (si le premier noeud est une adresse nulle, cela représente une liste vide).
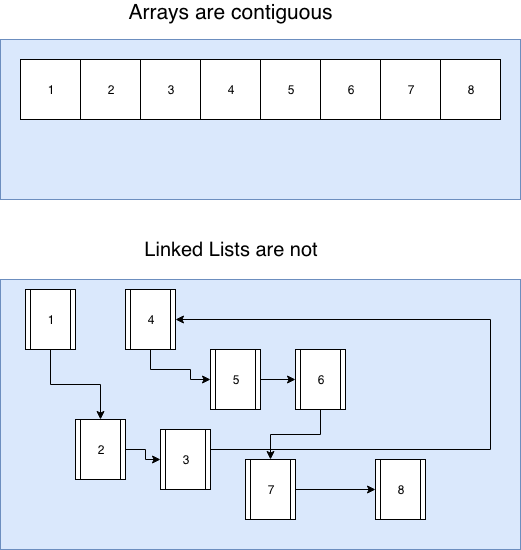
Avec une liste chaînée, nous ne pouvons pas accéder directement à un élément avec son index car l'ordinateur ne peut pas calculer son adresse mémoire. Il doit parcourir la liste noeud par noeud en O(n) : c'est le premier inconvénient majeur d'une liste chaînée.
En revanche, la structure dynamique d'une liste chaînée rend les choses beaucoup plus simples pour ajouter, supprimer ou insérer des données n’importe où dans la liste si nous avons l’adresse du noeud. Toutes ces opérations nécessitant un temps en O(n) pour un tableau sont maintenant faites en O(1) avec une liste chaînée.
Avec tout cela, nous devons garder à l'esprit que de tels avantages ont un coût en mémoire : pour chaque valeur, nous devons stocker un pointeur supplémentaire sur le noeud suivant (cela peut doubler la mémoire utilisée pour une même quantité de données par rapport à un tableau).
Objectifs
Créer notre propre structure de liste chaînée Jouer avec les pointeurs Itérer nœud par nœud (Boucle - Loop) Gérer l'allocation mémoire
Nous allons coder notre propre liste simple chaînée et avoir un aperçu rapide sur la façon d'effectuer des opérations d'insertion, de traversée et de mise à jour en utilisant des pointeurs.
Et ensuite ?
Une fois que nous avons compris l’intérêt de cette structure de données, nous pourrons peut-être nous renseigner sur la complexité algorithmique ou voir d'autres structures de données qui exploitent les avantages des listes chaînées : listes doubles (double linked lists), listes adjacentes (adjacancy lists), graphes, etc.
Nous pouvons également consulter les algorithmes de tri. pour comprendre pourquoi la plupart d’entre eux vont planter en performances si nous utilisons une liste liée au lieu d'un tableau (elles ne sont pas adaptées aux tris).
Implémentons la notre
Nous avons opté pour le C++ pour l'illustration du code, mais pas d'inquiétude, les autres langues utilisent la même logique et le plus souvent une syntaxe similaire. Nous allons d'abord utiliser les pointeurs bruts pour illustrer les mécanismes de cette structure de données et nous en ferons une version simplifiée utilisant le C ++ moderne à la fin.
La seule donnée que la classe stocke directement est un pointeur sur le premier nœud (tête). La déclaration du nœud (Node) de liste doit également être connue pour pouvoir être gérer (cela pourrait être une classe séparée):
template < typename T >
class LinkedList
{
public:
LinkedList() : head(nullptr) {} // Construct as an empty list
private:
// Node structure declaration
struct Node
{
// Constructor
Node(const T& data) : data(data), next(nullptr) {}
T data; // Value
Node* next; // Pointer to the next node
};
Node* head; // Pointer on the first element
}
Insérer un nouvel élément
Pour insérer un élément au début de la liste, nous devons d’abord allouer de la mémoire pour créer le nouveau nœud. Ensuite, nous plaçons le pointeur du prochain noeud vers la tête de la liste et nous mettons à jour la nouvelle tête de la liste.
[...]
public:
void PushFront(const T& data)
{
Node* newNode = new Node(data); // Allocate memory
newNode->next = head; // Set the next node to be the head
head = newNode; // Set head to the new node
}
[...]
Et si nous voulons pouvoir pousser des éléments à la fin de la liste en O (1)? Nous pouvons simplement garder dans la classe un pointer vers le dernier nœud (tail).
L'image ci-dessous illustre l'opération d'insertion et montre que le code utiliserait la même stratégie quelle que soit la position de l'insertion dans la liste.
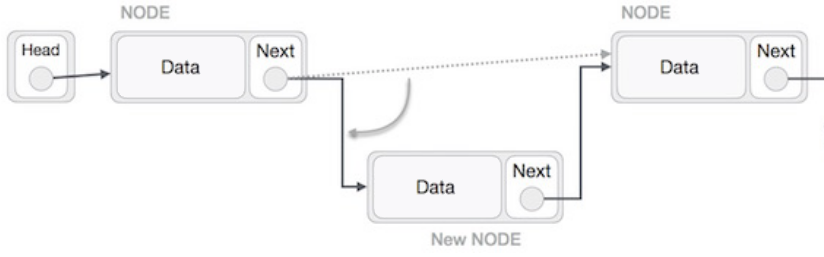
Attention, il ne faut pas oublier le destructeur pour éviter les fuites mémoire !
C’est crucial car de nouveaux nœuds seront créés à l’aide de la mémoire allouée dynamiquement par conséquent, ils doivent désallouer lorsque la liste est détruite. Le destructeur illustre aussi parfaitement comment parcourir une liste noeud par noeud.
[...]
public:
// Destructor - Traverses over the list and frees up the memory used by each node
~LinkedList() {}
{
Node* current = head; // Start on head
while (current != nullptr) // While there is node behind the pointer
{
Node* next = current->next; // Get the next from current
delete current; // Delete the current
current = next; // Move current to the next
}
}
[...]
Parfait ! Nous avons toutes les connaissances nécessaires pour créer les autres méthodes / fonctions que nous souhaitons. Pour pratiquer, nous recommandons d'essayer d'implémenter PopNode(int index) qui supprime un noeud à une position donnée (index).
Version utilisant du C++ moderne
La même structure de données codée en C++ moderne est beaucoup plus compacte et évite d'avoir à gérer l'allocation mémoire en changeant uniquement Node* en unique_ptr< Node > :
[...]
// No constructor needed as unique_ptr is by default set to nullptr
// No destructor needed using unique_ptr as the memory is freed with the owner
void PushFront(const T& data)
{
auto newNode = unique_ptr(new Node(data)); // Allocate memory
newNode->next = move(head); // Set the new node to own the current head
head = move(newNode); // Set the new head to own the new node
}
[...]