Introduction
A linked list is the other most fundamental data structure : as an array, it is also a way to store a collection of elements. However, instead of storing data in fixed contiguous memory, a linked list is a collection of nodes that are connected by links and may be found anywhere in the memory space.
Each data in memory has an address, you can always get the address from the data variable and access the data value from its address. The idea is simple then, we have access to the first node which contains : its data and the address to the next node. A null pointer (nullptr) indicates that the end of the list has been reached (if the first node is a null pointer address then this represents an empty list).
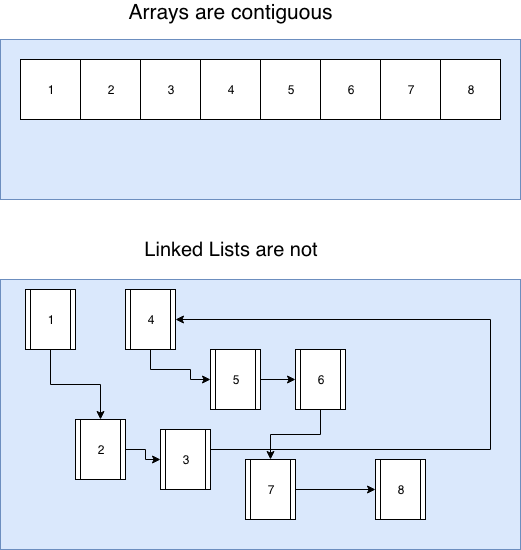
With a linked list we cannot access to an item directly using its index because the computer cannot calculate its memory address, it has to go through the list node by node in O(n). This is the first major drawback of a Linked List.
On the other hand, the dynamics of this data structure makes it the simplest things to add, remove or insert nodes from anywhere in the list if we have the node address. All of these operations that require O(n) time for an array are now made in O(1) with the linked list.
With all of this, we have to keep in mind such huge benefits have a cost in the memory : for each value we have to store an extra pointer to the next one (it may double the memory used for the same amount of data compared to an array).
Objectives
Create our own linked list structure Play with pointers Iterate node by node (Loop) Manage memory allocations
We will code our own simple linked list to have a quick overview on how to perform insertion, traversal and update operations using pointers.
What is next?
Once we understand the interest of this data structure, we may go to read about complexity or look after other data structures that exploit linked list advantages : double linked lists, adjacency lists, graphs...
We may also have a look at sorting algorithms to understand why most of them will crash in performances if we were using a linked list instead of an array (linked list are not adapted for reordering).
Build our own
We will have opted for a C++ with a template for the code illustration, but do not worry, the other languages use the same logic and most often a similar syntax. We will first use a raw pointer to illustrate the mechanism of this data structure and we will make a simplified version using modern C++ at the end.
The only data that the class directly stores is a pointer on the first node (head). The declaration of the list node's must also be known to be able to handle it (it could be an independent class) :
templateclass LinkedList { public: LinkedList() : head(nullptr) {} // Construct as an empty list private: // Node structure declaration struct Node { // Constructor Node(const T& data) : data(data), next(nullptr) {} T data; // Value Node* next; // Pointer to the next node }; Node* head; // Pointer on the first element }
Insert new element
To insert an element at the beginning of the list, we first need to allocate memory to create the new node. Then, we set the node pointer next to point to the head of the list and update the new head of the list.
[...]
public:
void PushFront(const T& data)
{
Node* newNode = new Node(data); // Allocate memory
newNode->next = head; // Set the next node to be the head
head = newNode; // Set head to the new node
}
[...]
What if we want to be able to push elements at the end of the list in O(1) ? We may keep track of the tail node within the LinkedList.
The image below illustrates the insert operation and shows the code would use the same strategy whatever the position of the insertion is in the list.
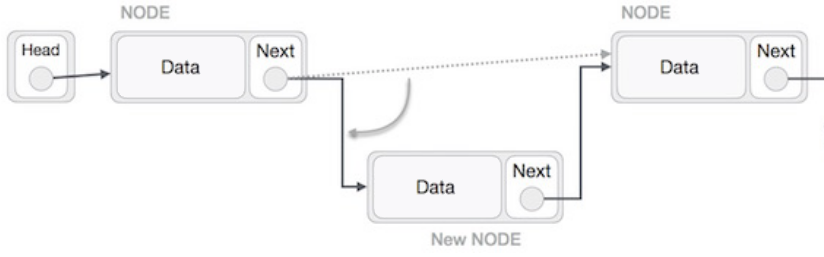
Be careful : the destructor must not be forbidden to avoid memory leaks !
This is crucial as new nodes will be created using dynamically allocated memory and hence they need deallocating when the list is destroyed. The destructor also perfectly illustrates how to traverse a list.
[...]
public:
// Destructor - Traverses over the list and frees up the memory used by each node
~LinkedList() {}
{
Node* current = head; // Start on head
while (current != nullptr) // While there is node behind the pointer
{
Node* next = current->next; // Get the next from current
delete current; // Delete the current
current = next; // Move current to the next
}
}
[...]
Well done ! We have all the knowledge needed to make the other methods / functions we want. To practice, we recommend trying to implement oneself PopNode(int index) that remove a node at a given position (index).
Cleaner version using modern C++
The same data structure coded using modern C++ is much more compact and avoid to deal with memory management by only changing Node* to unique_ptr< Node > :
[...]
// No constructor needed as unique_ptr is by default set to nullptr
// No destructor needed using unique_ptr as the memory is freed with the owner
void PushFront(const T& data)
{
auto newNode = unique_ptr(new Node(data)); // Allocate memory
newNode->next = move(head); // Set the new node to own the current head
head = move(newNode); // Set the new head to own the new node
}
[...]