
Traces by a Quick Select looking for the 25th on random sequence {100} (rand picking)
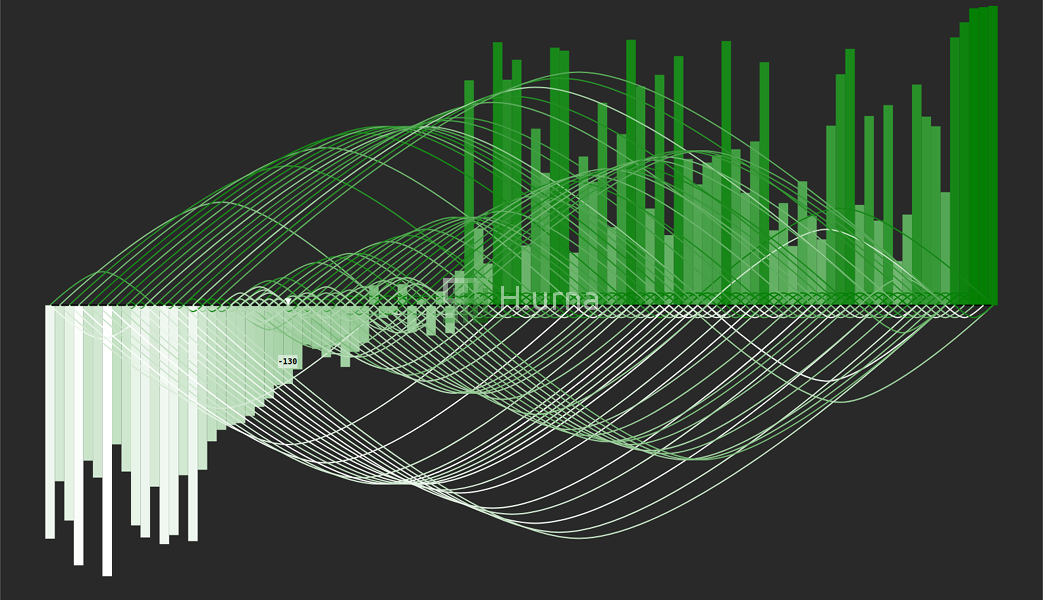
Traces and Values by a Quick Select looking for the 25th on random sequence {100} (rand picking)

Traces by a Quick Select looking for the 50th (median) on random sequence {100} (rand picking)
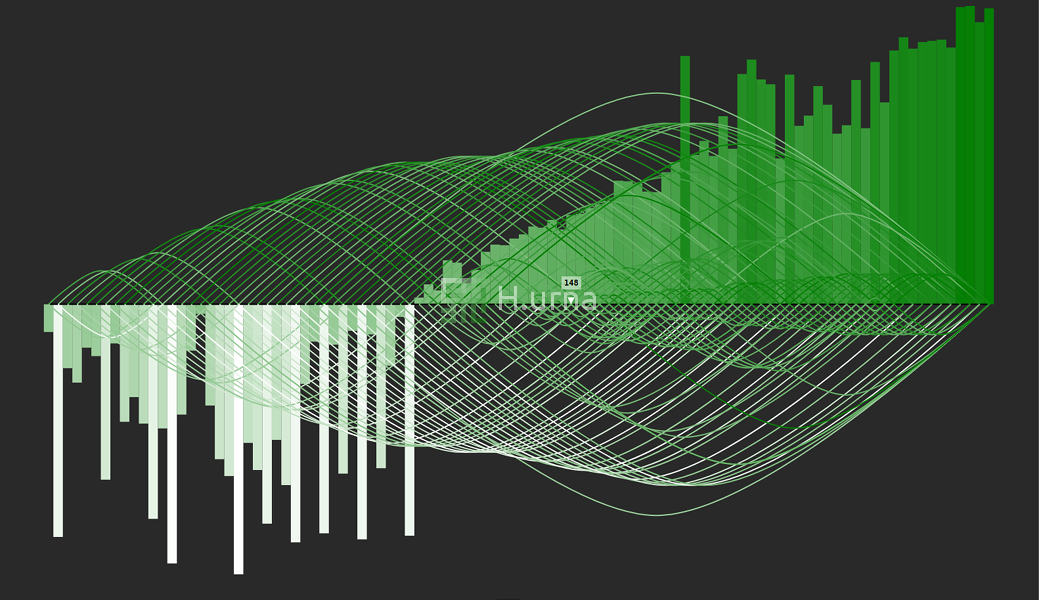
Traces and Values by a Quick Select looking for the 50th (median) on random sequence {100} (rand picking)
Quick Access
 Play online
Play online
 C++ Source Code
C++ Source Code
Description
Problem
Given a random sequence, find the kth largest or smallest element.
A simple approach would be first to sort the sequence, making this algorithm at best an O(n log n) time complexity. Another approach to perform the same task in O(n) expected time is using QuickSelect.
Considering a list that contains 1 million items: - If we perform a sort we could make it doing 20 million operations. - With a QuickSelect we will most likely find it with 1 million operations.
Applications
- Find the K’th smallest element.
- Find the K’th largest element.
- Find the K smallest elements.
- Find the K largest elements.
Dependencies
- Use Partition-Exchange algorithm as a subroutine
Homonyms
- Hoare's selection algorithm (developed by Tony Hoare)
How To Build
The Quickselect algorithm, also called Hoare's selection (Tony Hoare being the Quicksort developer), is a beneficial divide-and-conquer algorithm allowing to efficiently find the K'th order statistic in an efficient average-case manner: O(n). However, just like Quicksort, it has poor worst-case performance.
Quickselect and its variants are still the selection algorithms most often used in real-world implementations.
Quickselect uses the same overall approach as quicksort. It first chooses a pivot and makes the partitioning (split the data into two sub-sequences, accordingly as less than or higher than the pivot). However, instead of recursing into both sides, Quickselect only recurses into one side: the side with the element it is searching for. It then stops when the pivot itself is the k’th ordered element.
We have chosen to expose here a recursive version of the algorithm to make it easier to read.
Steps
- 1. Pick an element, called a pivot, from the array.
- 2. Partition: divide the array into two partitions such that:
- All elements less than the pivot must be in the first partition.
- All elements higher than the pivot must be in the second partition.
- 3.a If the new pivot index is k, we are done: return the pivot.
- 3.b If the new pivot index is greater than k: recurse on the left side.
- 3.c If the new pivot index is smaller than k: recurse on the right side with k --> k - new pivot index (recursion offset).
Code
Iterator KthOrderStatistic(Iterator begin, Iterator end, unsigned int k)
{
// Sequence does not contain enough elements: Could not find the k'th one.
auto size = distance(begin, end);
if (k >= size)
return end;
auto pivot = PickPivot(begin, end); // Take random pivot
auto newPivot = Partition(begin, pivot, end); // Partition
// Get the index of the pivot (i'th value)
auto kPivotIndex = distance(begin, newPivot);
// If at the k'th position: found!
if (kPivotIndex == k)
return newPivot;
// Recurse search on left part if there is more than k elements within the left sequence
// Recurse search on right otherwise
return (kPivotIndex > k) ? KthOrderStatistic(begin, newPivot, k)
: KthOrderStatistic(newPivot, end, k - kPivotIndex);
}
Visualization
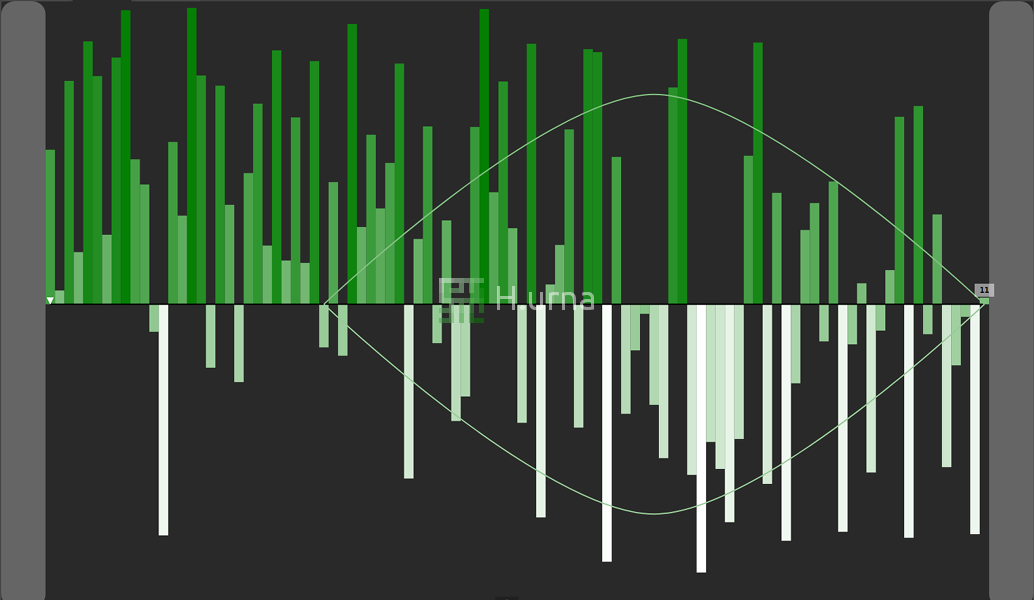
1. A random pivot is picked {11} and the partition starts (the pivot is moved to the end of the active sub-sequence).
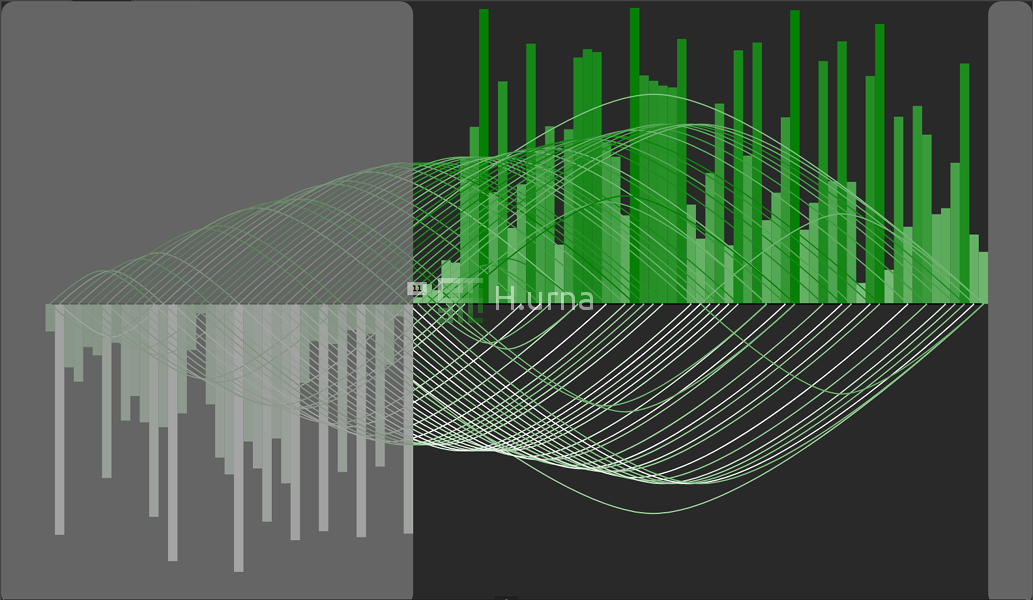
2. At the end of the first partition the 50th order statistic (median) value appears to be bigger than {11}: recurse the search within the right sub-sequence.

3. After few more iterations, the scope around the kth element gets mostly reduced.
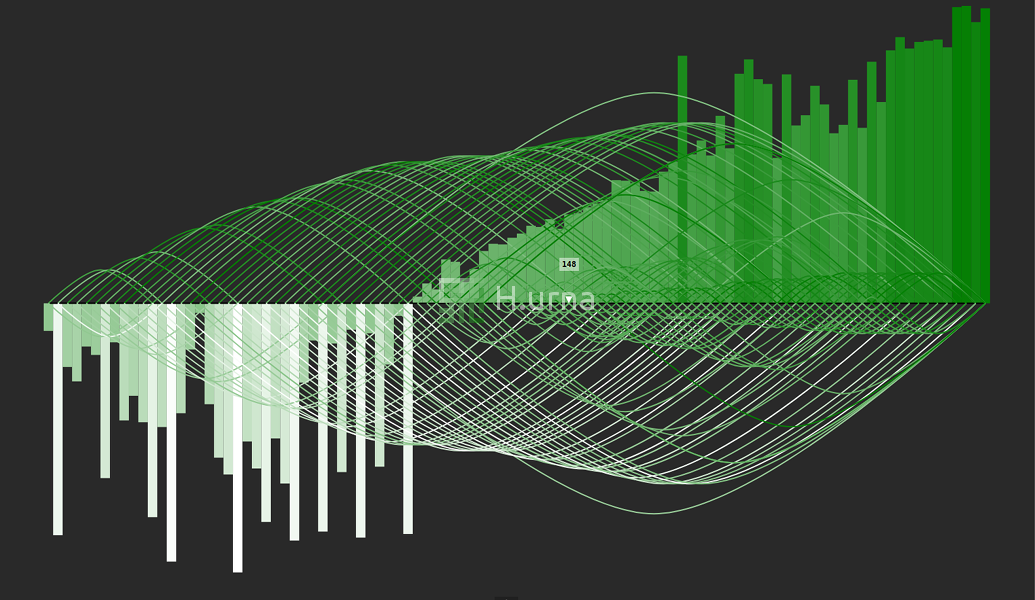
4. Search done: the 50th order statistic (median) of this sequence is equal to {148}.
Picking Strategies
As seen above, Quick Select picks an element as pivot and partitions the given array around the picked pivot. The pivot selection can be made in several different ways, and the choice of specific implementation schemes significantly affects the algorithm's performance. Here are some strategies:
- Always pick the first element.
- Always pick the last element.
- Always pick the middle element.
- Pick a random element.
- Pick median (based on three value) as the pivot.
Like quicksort, the quickselect has excellent average performance, but is sensitive to the pivot that is chosen. Please refer to Quicksort article to visually compare those strategies.
Complexity
Reminder
The in-place version of a Partition has a time complexity of O(n) in all case and a space complexity of O(1).
Useful mathematical theorems:
$$\sum_{i=0}^{n-1} ar^i = a(\frac{1-r^n}{1-r})$$ $$\sum_{i=0}^{n-1} n = n(n-1)$$ $$\sum_{i=0}^{n-1} i = \frac{n(n + 1)}{2} - n = \frac{n(n - 1)}{2}$$ $$\sum_{i=0}^{n-1} (n+i) = \sum_{i=0}^{n-1} n + \sum_{i=0}^{n-1} i$$Time
Best
The best configuration occurs when the first selected pivot is the k'th value: Partition-Exchange occurs only once, leading to a complexity of O(n).
Average
In average, the partitioning should ignore half the list each time it passes through it. After the first partitioning, we recurse the search on the lower/upper ~half and so on:
Sequences
$$a_0 = n$$ $$a_1 = \frac{n}{2}$$ $$a_2 = \frac{n}{4}$$ $$...$$ $$a_i = \frac{n}{2^n}$$
Computation
$$T(n) = n + \frac{n}{2} + \frac{n}{4} + ... + \frac{n}{2^n}$$ $$T(n) = n*(1 + \frac{1}{2} + \frac{1}{4} + ... + \frac{1}{2^n})$$ $$T(n) = n\sum_{i=0}^{n-1} (\frac{1}{2})^n$$ $$T(n) = n\frac{1 - 0}{1-\frac{1}{2}}$$ $$T(n) = n\frac{1}{\frac{1}{2}} = 2n$$ $$T(n) \approx O(n)$$
Here a = 1 and r = 1/2.
Worst
The worst situation occurs when each Partition-Exchange divides the sequence into two sublists of sizes 0 and n − 1 (smallest or most significant value is picked). Consequently, there is n − 1 nested calls and QuickSelect behave precisely as a QuickSort:
Sequences
$$a_0 = n$$ $$a_1 = n - 1$$ $$a_2 = n - 2$$ $$...$$ $$a_i = n - i$$
Computation
$$S(n) = \sum_{i=0}^{n-1} (n-i)$$ $$S(n) = \sum_{i=0}^{n-1} n - \sum_{i=0}^{n-1} i$$ $$S(n) = n(n - 1) - \frac{n(n - 1)}{2}$$ $$S(n) = \frac{n(n - 1)}{2}$$ $$S(n) = k(n^2 - n)$$ $$S(n) \approx O(n^2)$$
This occurs for example in searching for the maximum element of a sorted sequence, picking the first element as the pivot each time.
Space
As a reminder: - In-place partitioning requires O(1) space. - Recursion is made only with one of the sub-sequence.
Best: no recursion is made at all --> O(1) space complexity (stack).
Average: As seen on time complexity each recursive call processes a list of half the size. Let us put this into a recurrence relation for the call stack usage and use the master theorem for divide-and-conquer recurrences again: $$T(n) = O(1) + T(\frac{n}{2}) --> O(ln(n))$$
Worst: As seen in time computation there is n − 1 nested calls --> O(n) space complexity (stack).