
Traces laissées par un QuickSelect recherchant la 25e valeur sur une séquence aléatoire de 100 élements (avec une sélection du pivot aléatoire)
.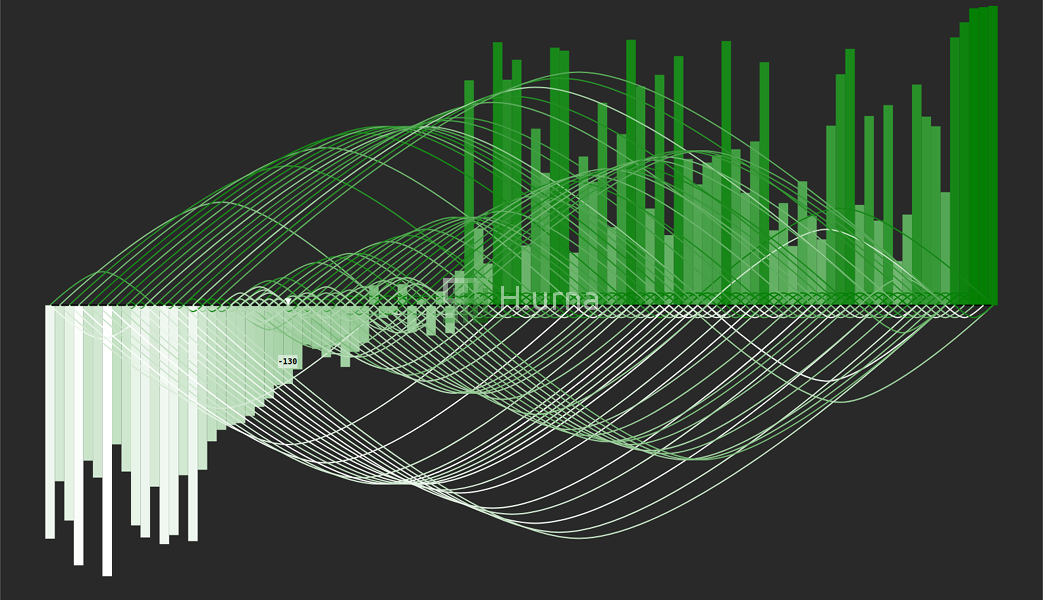
Traces et valeurs après un QuickSelect recherchant la 25e valeur sur une séquence aléatoire de 100 élements (avec une sélection du pivot aléatoire)
.
Traces laissées par un QuickSelect recherchant la 50e valeur (median) sur une séquence aléatoire de 100 élements (avec une sélection du pivot aléatoire)
.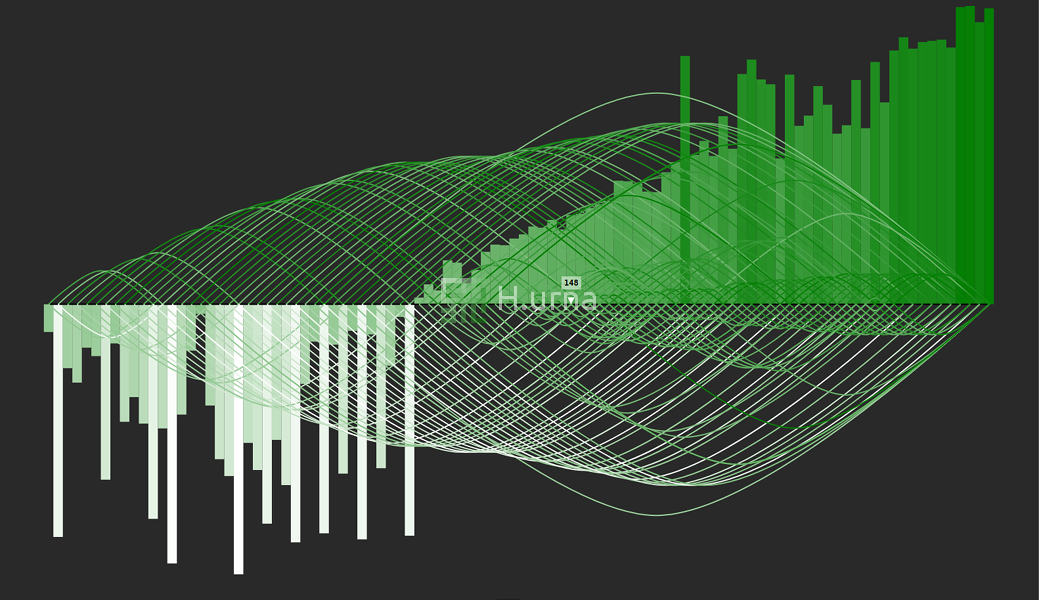
Traces et valeurs après un QuickSelect recherchant la 50e valeur (median) sur une séquence aléatoire de 100 élements (avec une sélection du pivot aléatoire)
Accès Rapide
 Jouer en ligne
Jouer en ligne
 Code Source C++
Code Source C++
Introduction
Problème
Depuis une séquence aléatoire, trouver le(s) n('ème) élément(s) le(s) plus grand(s) ou le(s) plus petit(s).
Une approche simple consisterait à commencer par trier la séquence, faisant de cet algorithme une complexité temporelle optimalle en O(n log n). Une autre approche pour effectuer la même tâche dans un temps attendu O(n) utilise QuickSelect.
Considérons une liste contenant 1 million d'éléments : - Si nous effectuons un tri, nous pourrions trouver la solution en effectuant 20 millions d'opérations. - Avec un QuickSelect, nous la trouverons très probablement avec seulement 1 million d'opérations.
Applications
- Rechercher le nième plus petit élément.
- Rechercher le nième le plus grand élément.
- Rechercher les n plus petits éléments.
- Recherchez les n plus grands éléments.
Dépendances
- Utilise l'algorithme de Partition en fonction auxiliaire.
Homonymes
- Algorithme de sélection de Hoare (crée par Tony Hoare)
- Statistique d'ordre de rang k (K'th order statistic)
Construction
L'algorithme Quickselect, ou sélection de Hoare (Tony Hoare étant aussi le créateur du Quicksort), est un algorithme régis par le paradigme diviser pour mieux régner. Il permet de trouver efficacement la statistique d'ordre de rang k : en moyenne en O(n). Toutefois, tout comme le Quicksort, ses performances sont mauvaises dans le pire des cas.
Quickselect et ses variantes restent les algorithmes de sélection les plus utilisés dans les implémentations du monde réel.
Quickselect utilise la même approche globale que quicksort. Il choisit d’abord un pivot et effectue le partitionnement (scinde le tableau en deux sous-séquences : celle des éléments inférieurs et celle des éléments supérieurs au pivot). Cependant, au lieu de réitérer le process dans chaque sous-séquence, QuickSelect le fait uniquement dans l'une d'elle : celle contenant l'élément qu'il recherche (selon si il est supérieur ou inférieur au pivot). Il s’arrête ensuite lorsque le pivot lui-même est le nième élément le plus grand.
Nous avons choisi de vous exposer ici une version récursive de l'algorithme pour des questions de lisibilité.
Etapes
- 1. Prendre un élément dans le tableau, il sera appelé pivot.
- 2. Partition : diviser le tableau en deux partitions tels que :
- Tous les éléments inférieurs au pivot doivent être dans la première partition.
- Tous les éléments supérieurs au pivot doivent être dans la deuxième partition.
- 3.a Si le nouvel indice de pivot est k, nous avons terminé : renvoyer le pivot.
- 3.b Si le nouvel indice de pivot est supérieur à k : faire une recursion sur le sous tableau de gauche.
- 3.c Si le nouvel indice du pivot est inférieur à k : faire une recursion sur le sous tableau de droite avec n = n - new pivot index (les k plus petits éléments étant restés dans le sous-tableau de gauche).
Code
Iterator KthOrderStatistic(Iterator begin, Iterator end, unsigned int k)
{
// Sequence does not contain enough elements: Could not find the k'th one.
auto size = distance(begin, end);
if (k >= size)
return end;
auto pivot = PickPivot(begin, end); // Take random pivot
auto newPivot = Partition(begin, pivot, end); // Partition
// Get the index of the pivot (i'th value)
auto kPivotIndex = distance(begin, newPivot);
// If at the k'th position: found!
if (kPivotIndex == k)
return newPivot;
// Recurse search on left part if there is more than k elements within the left sequence
// Recurse search on right otherwise
return (kPivotIndex > k) ? KthOrderStatistic(begin, newPivot, k)
: KthOrderStatistic(newPivot, end, k - kPivotIndex);
}
Visualisation
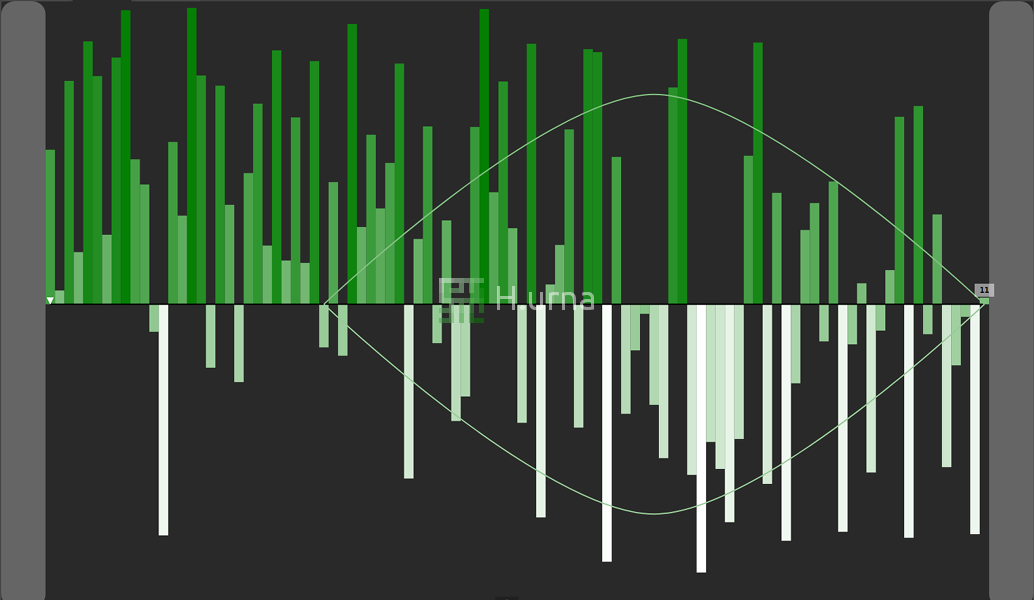
1. Un pivot aléatoire est sélectionné {11} et la partition démarre (le pivot est déplacé à la fin de la sous-séquence active).
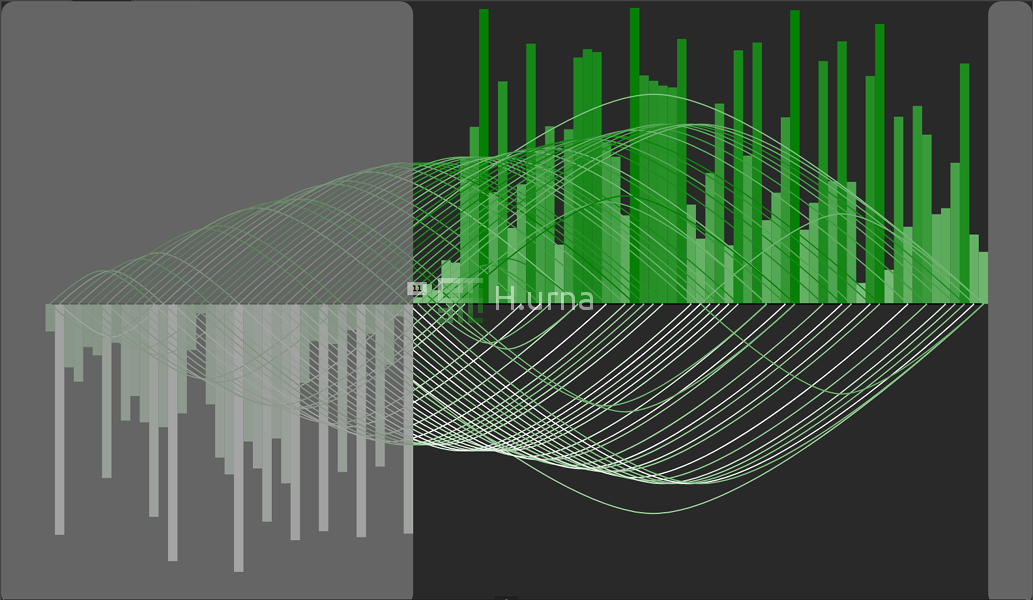
2. À la fin de la première partition, la statistique de 50ème ordre (médiane) semble être plus grande que {11} : la recherche est relancée dans la sous-séquence de droite.

3. Après quelques itérations supplémentaires, la portée autour du k'ème élément est grandement réduite.
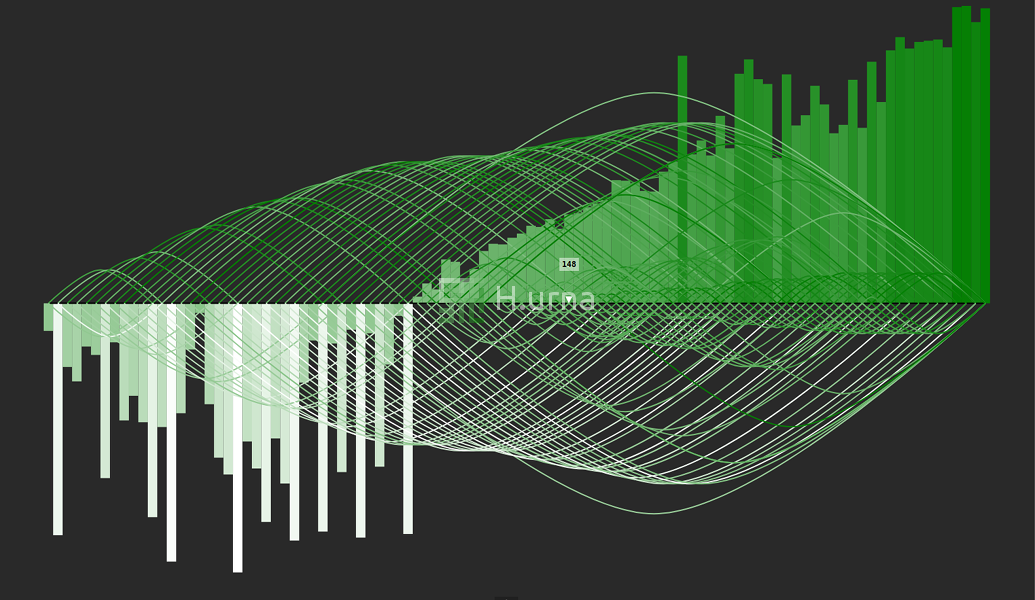
4. Recherche effectuée : la statistique d'ordre 50 (médiane) de cette séquence est égale à 148.
Choix du Pivot
QuickSelect choisit un élément comme pivot et partitionne le tableau selon celui-ci. La sélection du pivot est importante car elle peut être faite de plusieurs manières, et ce choix peut affecter grandement les performances de l'algorithme. Voici quelques stratégies possibles:
- Toujours prendre le premier élément.
- Toujours prendre le dernier élément.
- Toujours prendre l'élément du milieu.
- Prendre un élément au hasard.
- Prendre le median basé sur 3 valeurs.
Comme Quicksort, QuickSelect a de bonnes performances moyennes mais est sensible au pivot choisi, se référer à leurs comparaisons visuelles inclues dans l'article de l'algorithme du Quicksort.
Complexité
Théorèmes et égalités utiles
La version 'in-place' de l'algorithm de Partition a une complexité temporelle en O(n) dans tous les cas et une complexité mémoire en O(1).
Théorèmes mathématiques utiles:
$$\sum_{i=0}^{n-1} ar^i = a(\frac{1-r^n}{1-r})$$ $$\sum_{i=0}^{n-1} n = n(n-1)$$ $$\sum_{i=0}^{n-1} i = \frac{n(n + 1)}{2} - n = \frac{n(n - 1)}{2}$$ $$\sum_{i=0}^{n-1} (n+i) = \sum_{i=0}^{n-1} n + \sum_{i=0}^{n-1} i$$Temps
Meilleur
La meilleure configuration se produit lorsque le premier pivot sélectionné est la nième valeur : La partition ne se produit qu'une seule fois, conduisant à une complexité en O(n).
Moyen / Asymptotique
En moyenne, le partage doit ignorer la moitié de la liste à chaque récursion. Après le premier partitionnement, nous reprenons la recherche sur la partie inférieure ou supérieure seuleument et ainsi de suite.
Séquences
$$a_0 = n$$ $$a_1 = \frac{n}{2}$$ $$a_2 = \frac{n}{4}$$ $$...$$ $$a_i = \frac{n}{2^n}$$
Calcul - Somme
$$T(n) = n + \frac{n}{2} + \frac{n}{4} + ... + \frac{n}{2^n}$$ $$T(n) = n*(1 + \frac{1}{2} + \frac{1}{4} + ... + \frac{1}{2^n})$$ $$T(n) = n\sum_{i=0}^{n-1} (\frac{1}{2})^n$$ $$T(n) = n\frac{1 - 0}{1-\frac{1}{2}}$$ $$T(n) = n\frac{1}{\frac{1}{2}} = 2n$$ $$T(n) \approx O(n)$$
Ici a = 1 et r = 1/2.
Asymptotique
Le pire scénario se produit lorsque la partition produit deux sous-séquence de taille 0 et n − 1 (plus petite ou plus grande valeur a été choisie comme pivot). En conséquence, il va se produire n − 1 appels de fonctions imbriquées :
Séquences
$$a_0 = n$$ $$a_1 = n - 1$$ $$a_2 = n - 2$$ $$...$$ $$a_i = n - i$$
Calcul - Somme
$$S(n) = \sum_{i=0}^{n-1} (n-i)$$ $$S(n) = \sum_{i=0}^{n-1} n - \sum_{i=0}^{n-1} i$$ $$S(n) = n(n - 1) - \frac{n(n - 1)}{2}$$ $$S(n) = \frac{n(n - 1)}{2}$$ $$S(n) = k(n^2 - n)$$ $$S(n) \approx O(n^2)$$
Cela se produit par exemple lors de la recherche de l’élément maximal d’une séquence triée avec en statégie la sélection du premier élément comme pivot.
Espace Mémoire
Rappel : - La version 'in-place' de l'algorithm de Partition a une complexité mémoire en O(1). - La récursivité est effectuée uniquement avec l'une des sous-séquences.
Meilleur : aucune récursion n'est faite --> O(1) en espace dans la pile (stack).
Moyen: Comme on le voit sur la complexité temporelle, chaque appel récursif traite une liste diminuée de moitié à chaque étape. Mettons cela dans une relation de récurrence pour l'utilisation de la pile d'appels et utilisons à nouveau le Master théorème : $$T(n) = O(1) + T(\frac{n}{2}) --> O(ln(n))$$
Asymptotique : Comme vu pour la complexité temporelle, il y a n − 1 appels imbriqués --> O(n) en complexité spatialle (stack).